Whywhywhy
I co-founded Whywhywhy with Matt Holden in 2021. Whywhywhy was a team-based analytics app designed for broad appeal: Multiple use cases, multiple personas. We wanted to create an app with low floor and high ceiling so users could grow into more advanced use cases over time (like Excel or Tableau).
This writeup is a play-by-play of how we designed and built Whywhywhy. If you want to see what the finished product looked like, head over to whywhywhy.com. We also wrote a post mortem that goes deeper into the market and business.
Why does the world need another analytics app?
As product builders, we had used many analytics and business intelligence tools and were frustrated with their limits, mainly how they got in the way of our curiosity. Most business users we talked to felt a similar pain as they were trying to use data to answer questions. We heard a lot of frustration with current analytics tools, and most normal users still relied on spreadsheets as their data tool.

Curiosity turns into frustration when using data
Data infrastructure was also changing, with technologies like Snowflake, dbt, and the metrics layer promising a future beyond heavy BI tools. We also saw an opportunity in WebAssembly, Apache Arrow, and DuckDB—technologies that allowed the browser to handle large data processing tasks.
The no-code notebook
We set the audacious challenge: How would analytics work if we rethought the tool from the ground up? Looking at the existing landscape, we saw a few issues:
| Tool | Pros | Cons |
|---|---|---|
| Spreadsheets | Flexible Approachable |
Doesn't work with large datasets Charting is an afterthought Terrible for storytelling |
| Dashboards/BI | Good for monitoring Approachable |
Bad for exploration Bad for storytelling |
| Vertical analytics (Mixpanel, Amplitude, etc) |
Approachable | Inflexible—can’t bring in outside data |
Enter the notebook. We liked Jupyter and other computational notebooks for exploring data and communicating insights. The problem is that you have to know how to code, which makes it inaccessible to a broad audience.
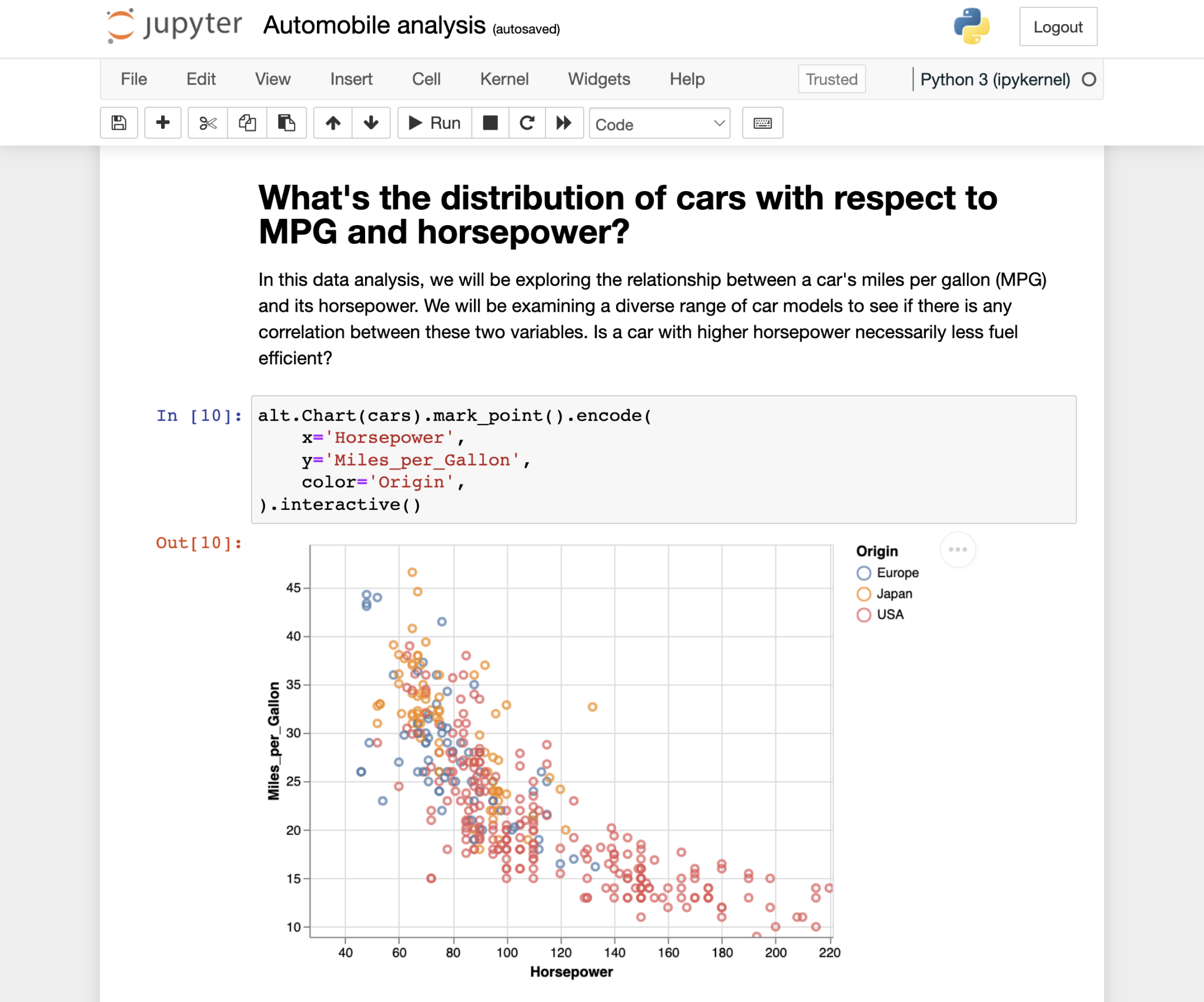
What if we could design a data format that took the best parts of the computational notebook but made it accessible to folks who don’t code?
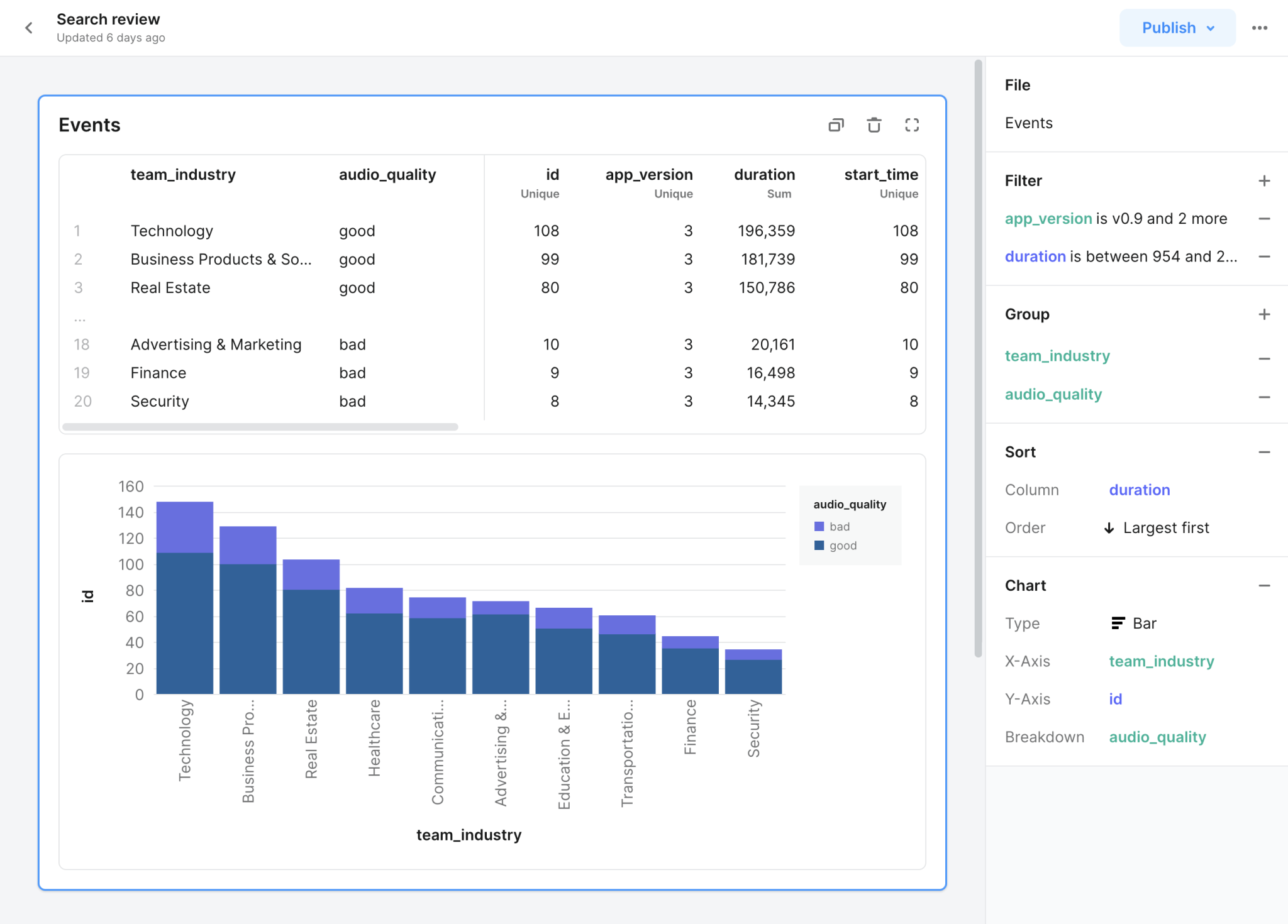
We started with a keyboard/natural-language-driven interface. The prototype above is one of the first we made to see if the concept had legs. As you can tell by the sample data, this was right during the COVID-19 pandemic.
We wanted a format that let you explore data and create a compelling narrative once you had found your insights. Above is a prototype of viewing a video narration embedded in an interactive document.
Users liked the speed (fast “time to table” and “time to chart”) and direct interaction paradigm (point-and-click instead of writing formulas) of the no-code notebook prototype we had made. The document format was less compelling, however. Users already have a go-to document tool and don’t necessarily want to add another one to the mix. One PM Director summarized the feedback well:
Most people don’t want to write or read long documents. What’s more interesting: How do you facilitate the conversation around the data?
The question card
Inspired by constrained communication formats like Instagram posts, we pivoted to a direction based on “question cards”. We designed question cards to be embeddable in other tools like Notion and Slack and tell a single data story.
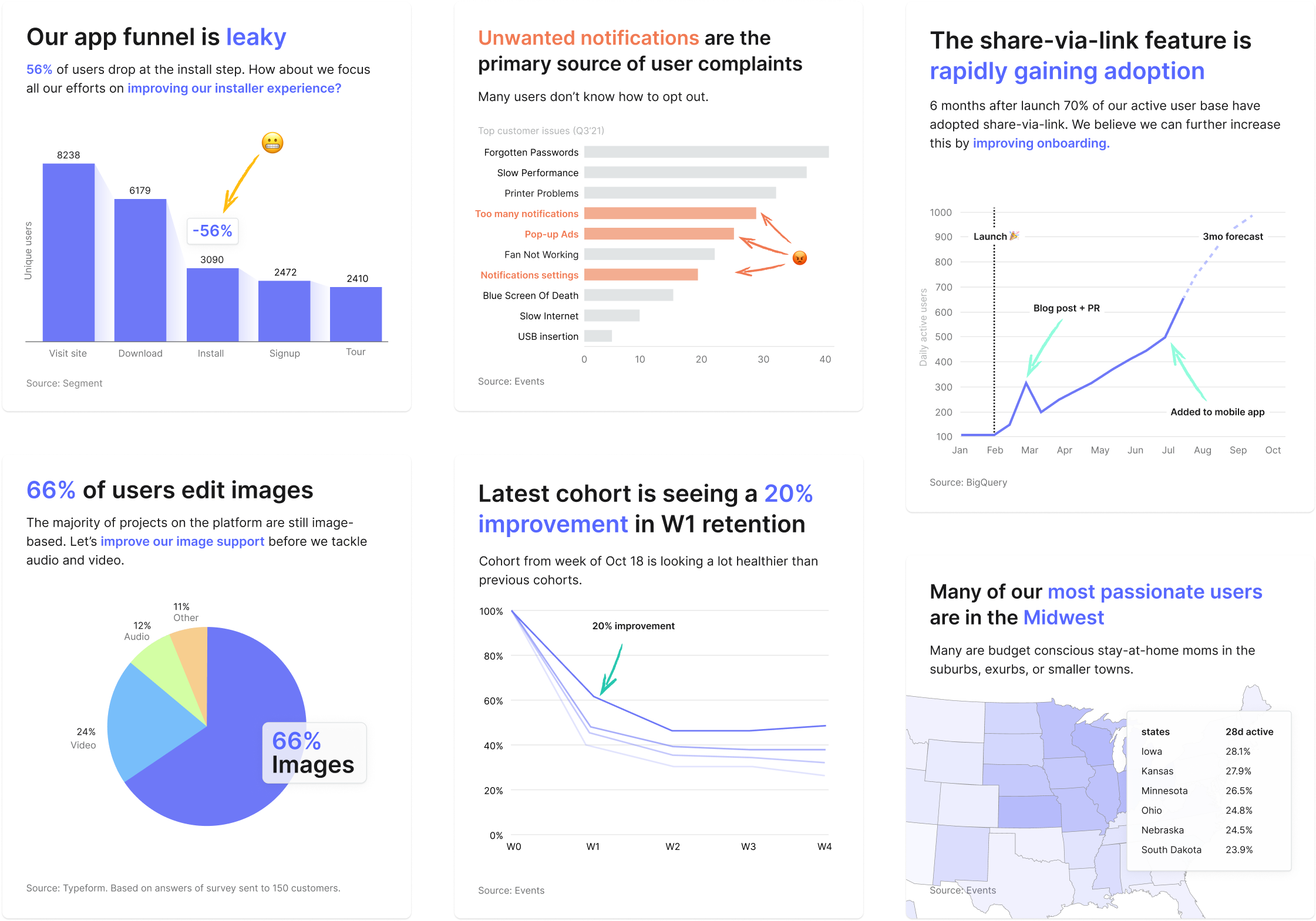
Above are some example data stories from our own work experience. This more straightforward, story-focused format resonated miles better with users.
To constrain the design space, we started with mobile as a canvas. It helped us identify which elements were minimally needed to create a compelling data story.
We re-engineered the notebook editor to resemble presentation software. Each card has a flexible recipe of transformation steps inspired by dplyr and node-based creative tools like Origami, Houdini, Max, etc.
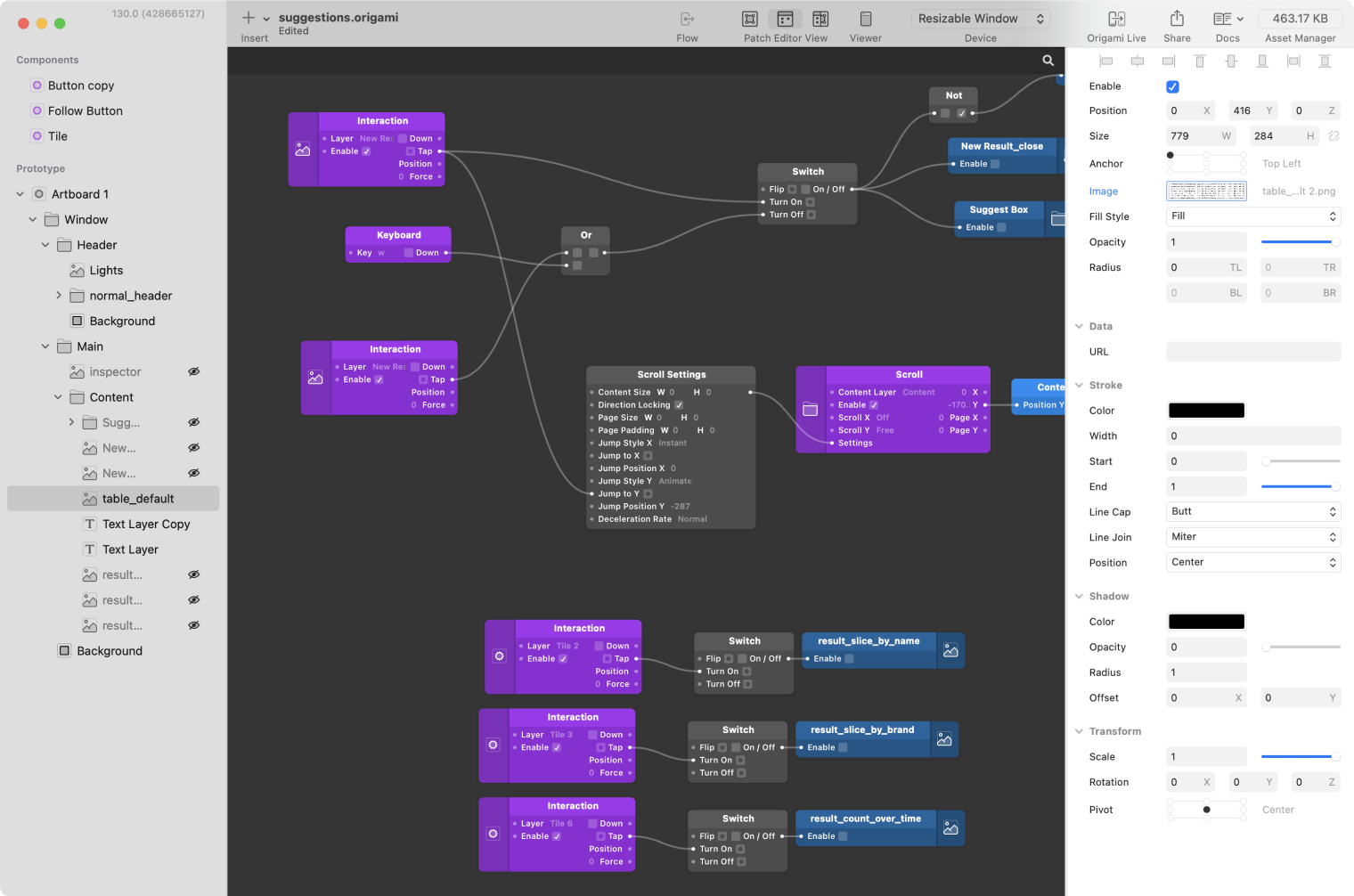
Origami’s building blocks can be assembled to create complex behavior

A dplyr pipeline using a small set of composable verbs
The idea was to provide the building blocks of data manipulation that users could use to assemble higher-level recipes that others could remix. We had left the concept of business users self-serving and felt that the challenge was to solve collaboration between business users and the more data-savvy folks in an organization.
After user testing the first card prototype, we dialed back the rigidity of the slide/presentation structure. We brought back the fast fluidity that we liked from the notebook while still keeping the “cards on a board” idea.
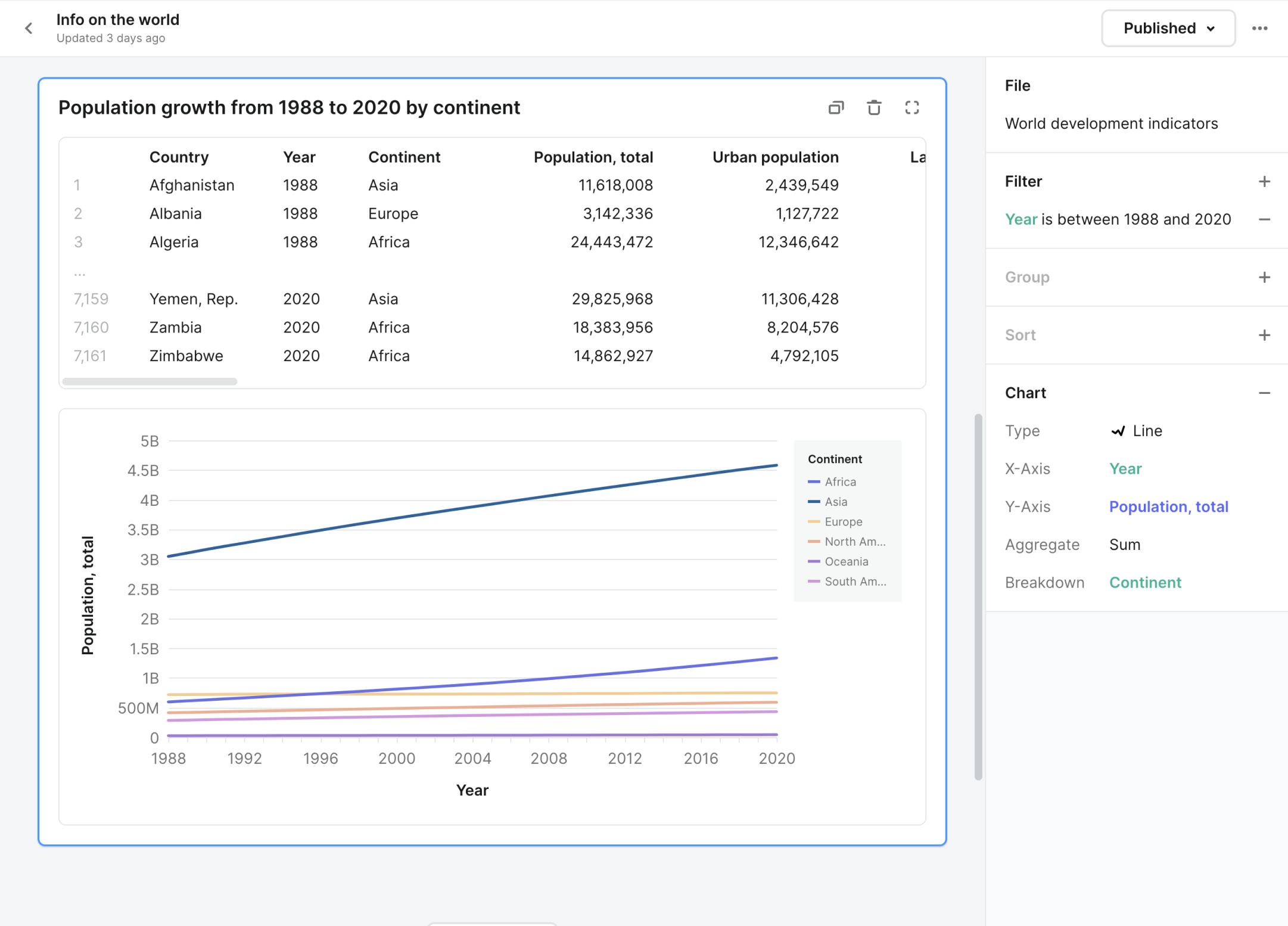
We designed question cards to follow a few principles:
- Cards should be portable. It should embed natively in your communication and document tools. Data is often one part of a bigger story and should fit in alongside other content.
- Cards should have a narrative. The best data communicators style and annotate their visualizations to guide viewers toward the vital point. Your data tool should also be a great storytelling tool.
- Cards should handle big data. A new data-sharing format shouldn’t break a sweat dealing with millions of rows of data.
- Cards should be inspectable. One of the drawbacks of CSVs, spreadsheets, or screenshots is that they sever the connection to the data source. Understanding the assumptions made to get to the conclusion leads to more informed discussion and better decisions.
- Cards should be beautiful by default. The best practices for designing legible charts are well understood, yet tools only help us a little. We should spend less time tweaking chart options and more time finding and communicating insights.
- Cards should start with a question. By thinking question-first instead of data-first, we focus our work and create insights for our team.
- Cards should be collaborative. Results should enable tweaking and iteration without fear of destroying someone else's work.
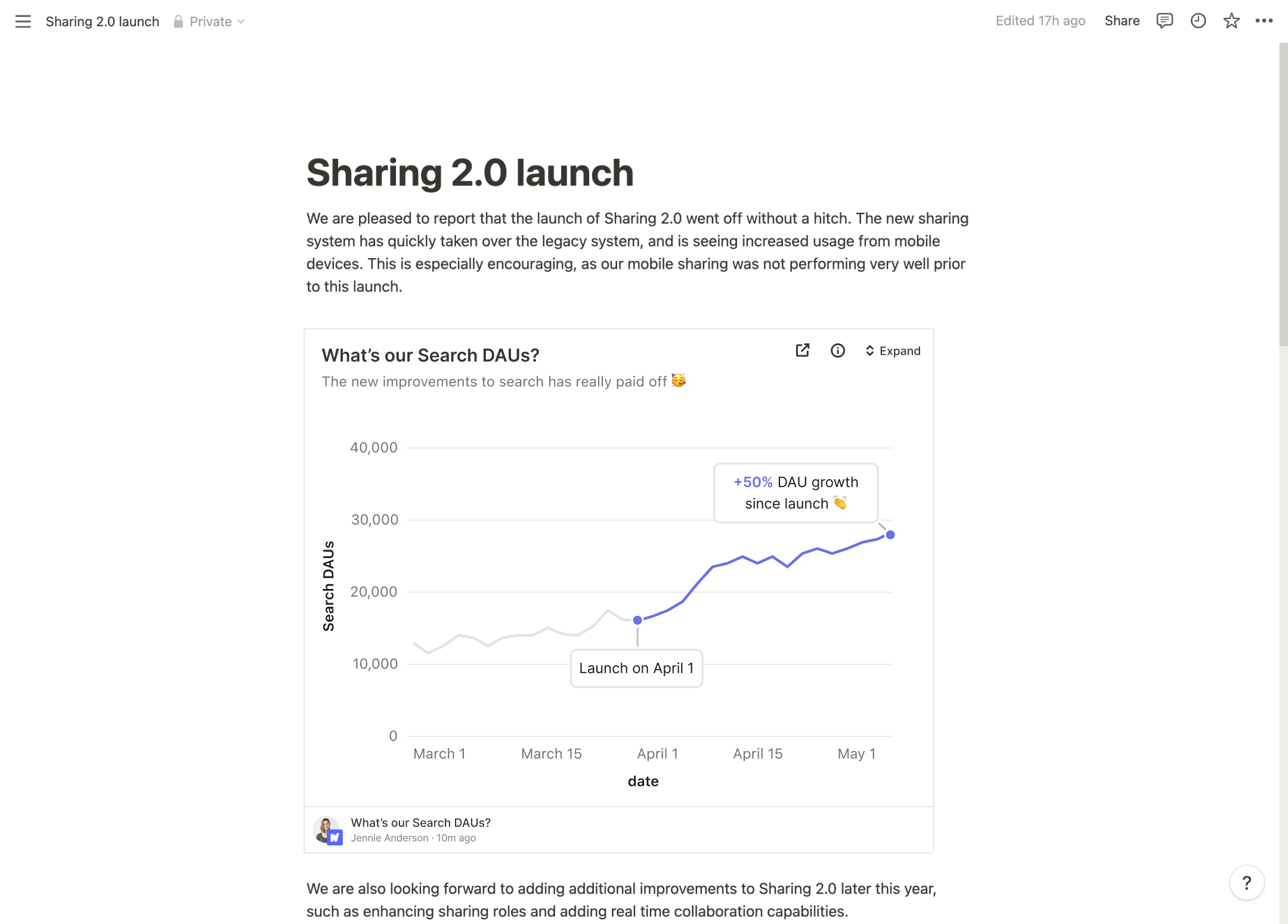
Interactive card embedded in Notion
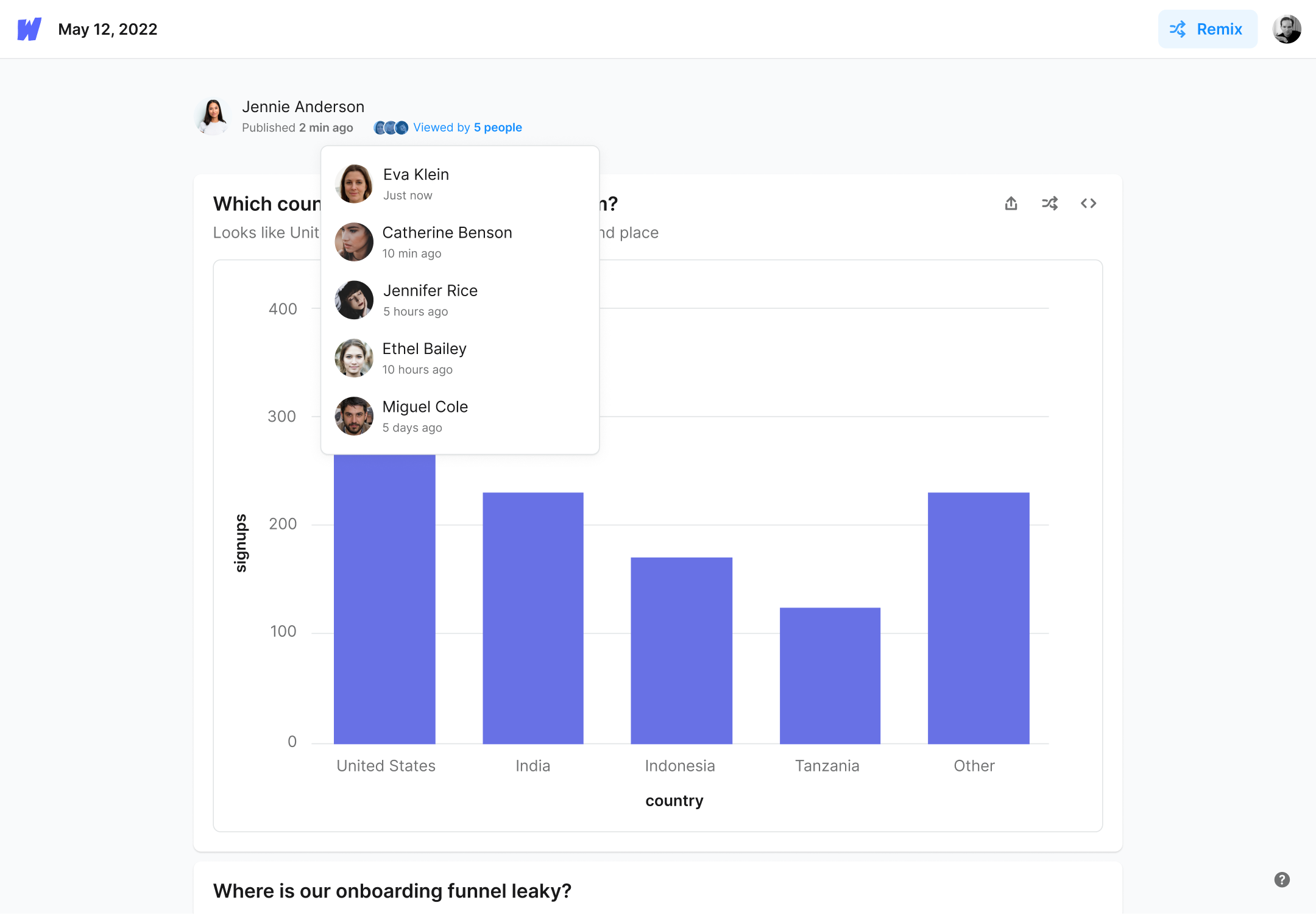
Explore the data and remix it to answer your own questions
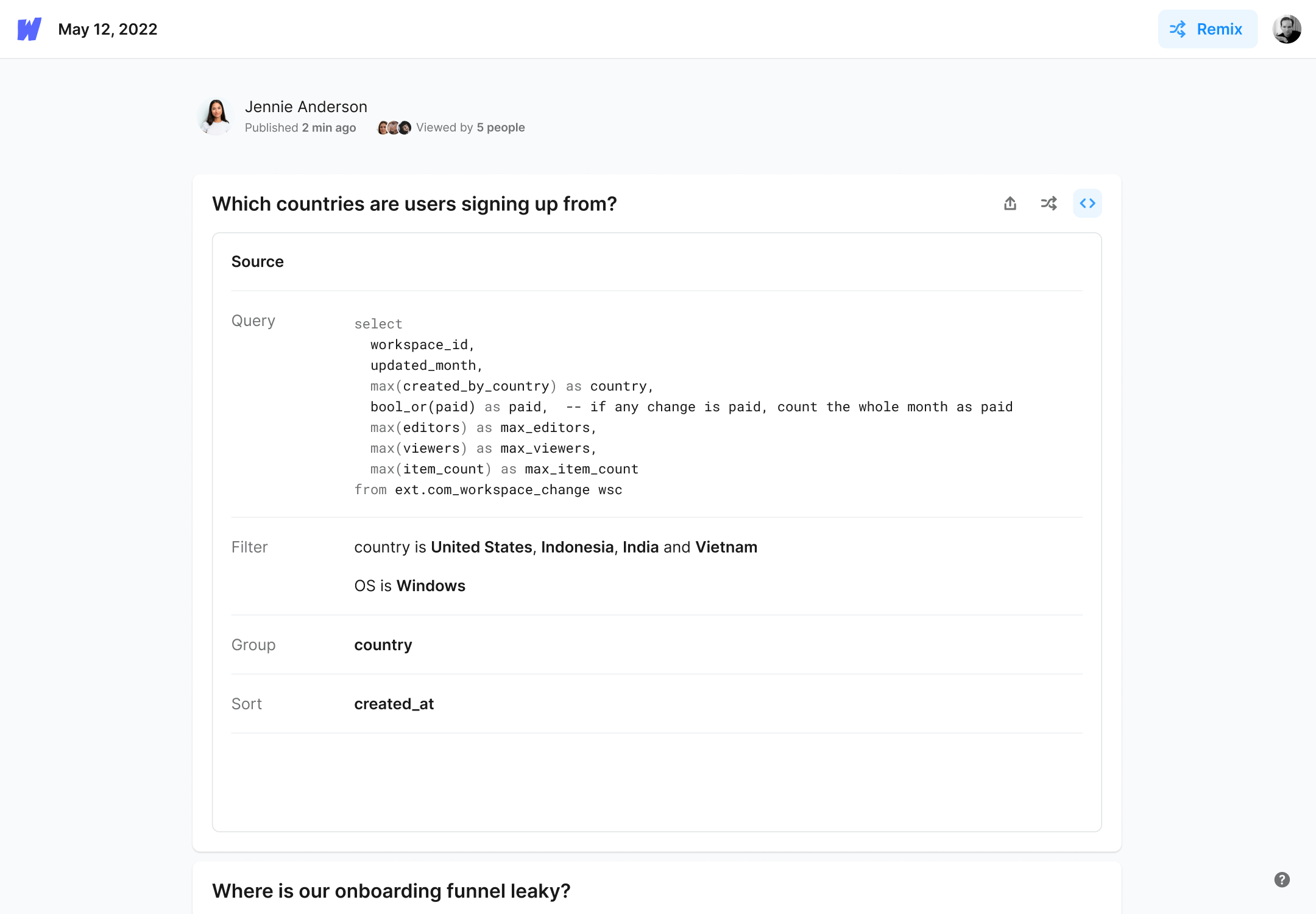
Viewers can inspect the source of any card to see how the analysis was done
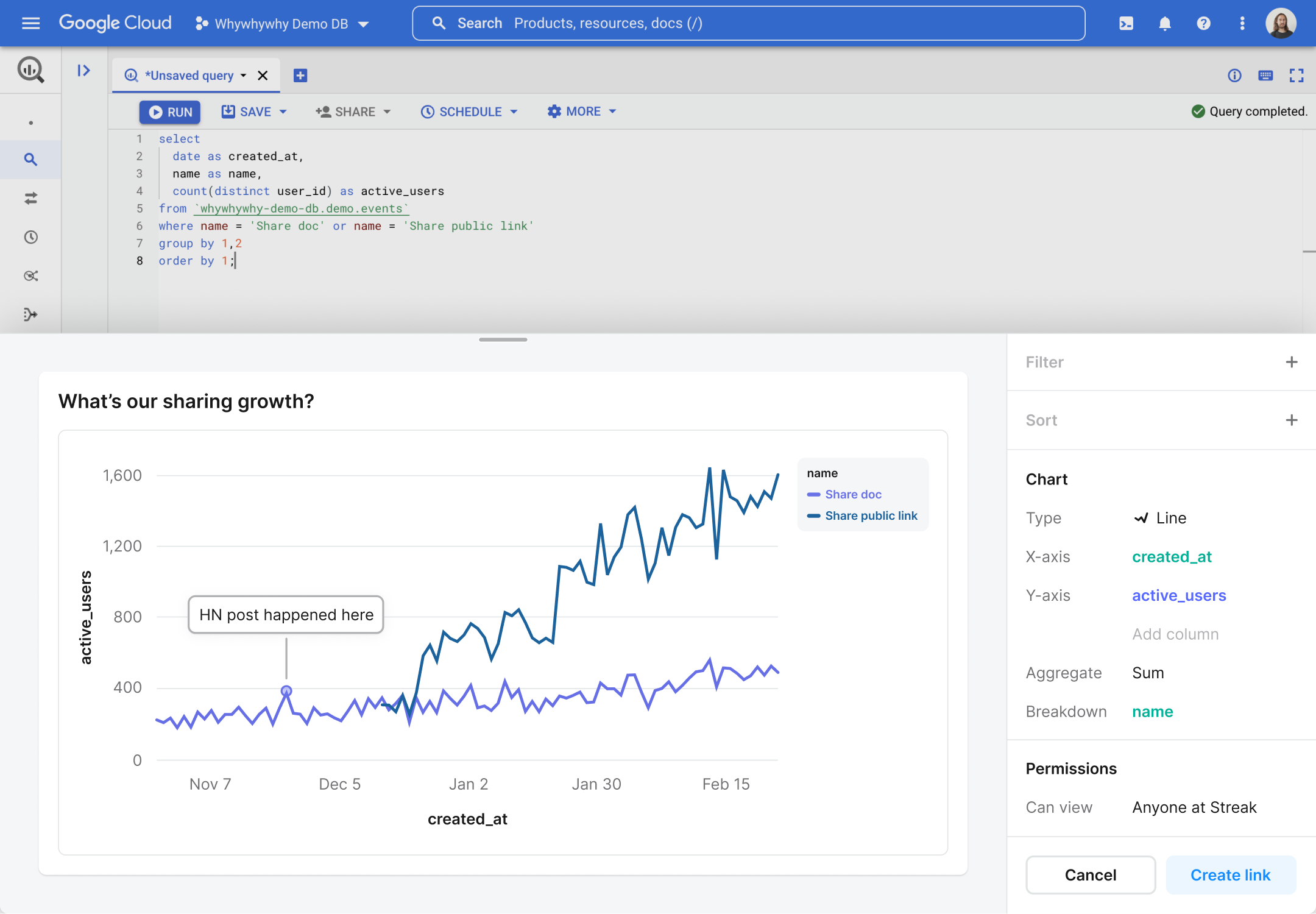
Create cards straight from your SQL editor using the browser extension
The brand
We wanted something that felt quirky and had a human touch. Existing tools used a lot of imagery of networks, computation, and automation. Because we believed in the importance of a human adding their narrative and judgment to the data, we wanted a brand identity with more humanity to it that reflected how we were different from other tools in space.
The name came from our focus on questions, and we liked that it was unique and memorable. So many startups are named some generic five-letter word. To be remembered, you have to be a bit weird sometimes.
While the app had an overall restrained visual identity, we sprinkled a playful hand-drawn look into places like thumbnail placeholders.

Icon set — 20x20

Color swatches
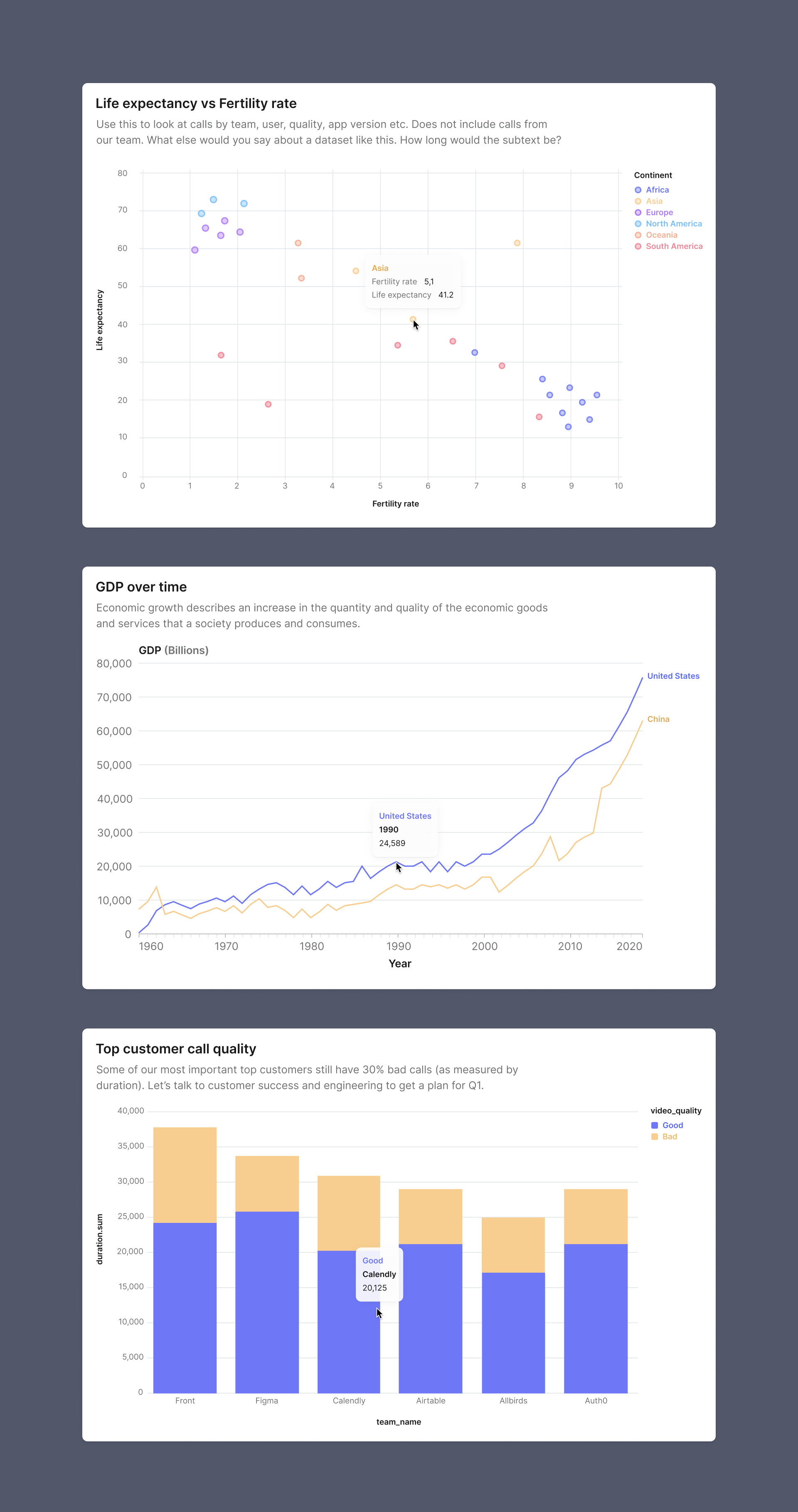
Whywhywhy chart style
Lessons learned
Designing a new general-purpose data analytics format was audacious. While we didn’t reach all the way, I think the principles we discovered are essential for improving how people answer questions using data and are mostly missing from today’s analytics tools.
We talked to hundreds of data users in various roles, learning about jobs to be done, ideal initial customers, and wedge use cases. It was exciting because the user pain was quite evident.
But adopting a data tool has significant frictions (data access and security are the main ones), and we found it hard to find a tight first use case where the value of solving it is larger than the cost of adoption.
As the data stack continues to improve over the next few years and makes it easier for end users to access clean, usable datasets securely, I’m sure we’ll see better analytics tools too.


